Раздел: Автоматизация > Практикум > Пишем систему автоматизированных тестов "с нуля"
Пишем систему автоматизированных тестов "с нуля"
Оглавление
Пару слов о том, кому это может пригодиться:
Данный материал в первую очередь адресован тем, кто уже имеет некий опыт автоматизации небольших и средних проектов, но, по какой-то причине, не представляет общей картины, либо не представляет в каких направлениях можно развивать автоматизированную систему. Все нижеизложенное основано, в первую очередь, на практическом личном опыте и, надеюсь, поможет вам правильно расставить приоритеты, сделать оценки и избежать подводных камней.
Удачной автоматизации и извините за англизмы...
1. Определяем требования к системе автоматизированного тестирования
Начало всех начал – выяснение того, что придется делать, иными словами – определение скоупа системы. Для успешного решения этой задачи лучше всего использовать технику брэйншторминга:
-
Соберите на митинг всех, кто заинтересован в автоматизации тестирования. Также пригласите тех, кто потенциально может получить выгоду (речь не только о финансовой выгоде) от внедрения автоматизации тестирования.
Коротко расскажите им об автоматизации – покажите на примерах как это поможет конкретно вам сделать процесс тестирования более эффективным. Какие будут получены преимущества в качестве конечного продукта, оценках тестопригодности билдов, увеличение объемов проверяемых данных.
Ваше видение автоматизации – это только часть той работы которую предстоит сделать. Чаще всего вы не знаете всех проблем проекта и всех пожеланий его участников. У каждого участника могут быть свои требования к новой системе (объем покрытия, фичи, сервисы). На этом этапе выпишите все идеи для системы автоматизированного тестирования (например – поддержка автотестестами нескольких платформ). Пока что избегайте критики каких-либо высказываний (и активно требуйте этого от других участников!) – просто перечисляйте то, что вам хотелось бы получить.
Когда все требования и идеи выписаны - приходит время трезвой оценки своих возможностей. Критически оцените написанное и выкиньте совсем уж бредовые идеи и требования. Если таковых не нашлось – с вами работают вполне вменяемые коллеги!
Расставьте приоритеты начиная с того, что проще всего сделать и что будет полезно (выгодно) наибольшему количеству участников. Помните правило – 20% функционала используются в 80% случаев! Найдите эти 20% и поставьте им высший приоритет. Лучше будет в первую очередь разрабатывать компоненты, которые можно сложить в законченную систему. Например, как в следующей главе.
2. Определение компонентов системы.
На самом деле у вас скорее всего будет ваша, эксклюзивная система с индивидуальным набором компонентов. Не факт, что вам пригодятся все компоненты, описанные ниже. Также, вероятно, для именно вашей системы, придется придумать дополнительные компоненты – для этого и нужно определить требования к ней (см. предыдущую главу). В любом случае, следующий перечень позволит представить и оценить некую типовую инфраструктуру автотестов и показать, что собственно тесты – это лишь небольшая (хоть и самая важная) ее часть.
- Автоматический инсталлятор приложения, а также сопутствующая ему функциональность для получения новой версии из репозитория, ftp, либо другого места куда автоматически выкладываются сборки поможет вам избежать выполнения всех этих действий вручную, а значит – освободит время на другие задачи.
- Автоматизированные тесты (скрипты + фреймворк для их выполнения). Этот компонент включает всю инфраструктуру тестов - компоненты для работы с удаленной и локальной файловой системой, сервисами/демонами, фреймворк для работы с формами приложения и, собственно, сами тест-скрипты. Только не спешите покрывать ими все приложение в самом начале разработки. Лучше имплементировать сразу только небольшую часть. Во-первых, имплементация всех тестов – это невероятно большой объем работы. Во-вторых - это не даст вам, впоследствии, заниматься другими задачами, так как будет требовать много времени на поддержку, запуск и рассылку результатов вручную. В-третьих – при последующей реализации других компонентов вы можете столкнуться с проблемой, решение которой потребует полного либо частичного изменения кода тестов – и чем меньше этого кода, тем оперативнее вы сможете его изменить. В общем, 2-4 тестов будет вполне достаточно для начала. После завершения реализации остальной инфраструктуры вы сможете к ним вернуться. На самом деле тесты – сами по себе большая тема. Подробнее об их рациональной организации – в последующих главах.
- Автоматический деинсталлятор приложения. Его лучше будет вызывать перед инсталляцией новой версии. Это также освобождает время на другие задачи. Вместо него можно использовать полное восстановление системы (например, из полного бэкапа диска). Такое восстановление дает гарантию отсутствия проблем из-за неверно функционирующей денисталляции, что идет на пользу стабильности автотестов.
- Автоматизированная система восстановления рабочей среды. Часто взаимодействие с системой – это необратимый процесс. Т.е. создав в ходе теста какой-либо элемент и использовав его в более сложных структурах вы теряете возможность удалить его из системы. Также если система осуществляет оборот документов – после изменения статуса документа вы не можете удалить документ, либо вернуть ему исходный статус. Часто невозможно создавать сущности с одинаковыми свойствами (например – пользователей с одинаковым именем). Для решения этих проблем необходима инфраструктура, обеспечивающая восстановление рабочей среды (уже установленного приложения + сопутствующего ПО) в эталонное состояние перед запуском каждого нового теста. Это требует дополнительного времени, но только так вы можете гарантировать отсутствие влияния результатов выполнения одного теста на последующие. Пример: в результате ошибки в приложении в системе сохранился пользователь с именем FIRST, это же имя используется для создания пользователя в ходе другого теста. Второй тест также всегда закончится ошибкой, так как пользователь FIRST уже существует. Самая простая реализация – это создание перед выполнением теста бэкапа изменяемых частей системы, если этот бэкап еще не был создан. Если бэкап существует (например был создан перед выполнением 1-го теста сразу после инсталляции приложения) – то восстановление состояния системы из этого бэкапа. Такая реализация позволяет создать «снимок» системы до того как первый тест будет выполнен и впоследствии использовать его для всех остальных тестов.
- Автоматизированная система хранения результатов автоматических тестов. Для построения графиков ретроспективы, выявления ошибок в тестах, оценки динамики роста/падения качества приложения необходимы не только последние, но и предыдущие результаты автоматических тестов. Лучше хранить их в базе данных, так как она обеспечивает более богатые возможности манипуляции данными. В моей практике также встречалась файловая система - для небольших проектов это допустимо, так как разработка предельно проста, но когда данных становится много скорость работы такой системы вызывает дискомфорт.
- Автоматизированная система формирования и рассылки результатов тестов. Сюда можно также добавить графики (но лучше - таблицы) истории выполнения автотестов со ссылками на соответствующие логи. Это отличный способ визуализации работы команды автоматизации! Текущее качество продукта, а также покрытие и качество тестов станут очевидны подписанным на данную рассылку. Это дает менеджерам проекта ощущение направления в котором движется разработка. А уже через пару месяцев любая задержка рассылки заставляет их нервничать и интересоваться причинами.
3. Определение компонентов для разработки
На самом деле в реальности ни одна разработка в наше время не делается полностью «с нуля», так как глупо не использовать уже готовые и достаточно стабильные компоненты и библиотеки. Скорее такая разработка сводится в выборе наиболее подходящих для задачи компонентов и написания интеграционного кода для них. Возможно, также, небольшая кастомизация компонентов с открытым кодом под собственные нужды (только не стоит увлекаться – можно получить несовместимость с обновлениями таких компонентов). Впрочем, если обновления для вас не критичны – дерзайте, но помните, что в них (обновлениях) может появиться нужный вам функционал, либо могут быть исправлены критические ошибки.
На данном этапе вы уже должны определиться со списком и приоритетами задач по автоматизации и решить, какие задачи решать с помощью готовых компонентов, а что разрабатывать самому. Я постараюсь перечислить модули и проекты, которые могут оказаться полезны при реализации компонентов, описанных в предыдущей главе.
- Автоматический инсталлятор приложения.
-
Для GUI инсталляций можно использовать любой инструмент, который поддерживает API целевой системы. Для Windows подойдет, например, AutoIT 3.
Silent install из командной строки поддерживается для многих типов инсталляторов.
OpenSsh поможет получить доступ к командной строке на удаленном сервере.
SFTP протокол позволит передавать файлы конфигурации на сервер и логи – обратно.
Jsch – java-библиотека, которая позволяет соединяться с удаленным сервером используя SSH и SFTP.
- Автоматизированные тесты (скрипты + фреймворк для их выполнения).
-
Для взаимодействия с файловой системой подойдут те же компоненты что и для инсталляции.
Для взаимодействия с GUI интерфейсами приложения можно воспользоваться как платными (QTP, WinRunner, SilkTest, Rational Functional Tester, TestComplete), так и бесплатными инструментами и java-библиотеками (HtmlUnit, HttpUnit, Selenium, WATIJ, Abbot) либо использовать другой инструмент, позволяющий распознавать элементы управления Вашего приложения.
- Автоматический деинсталлятор приложения.
-
Актуальны те же компоненты что и для автоматической инсталляции.
- Автоматизированная система восстановления рабочей среды.
-
DB-интерфейс используемой приложением базы данных позволит вам сделать бэкап и восстановить его. Многие базы используют интерфейс командной строки. В этом случае можно использовать те же компоненты что и для инсталляции.
Для доступа к web-интерфейсу можно использовать те же компоненты что и для тестов.
Манипулировать демонами и сервисами можно с помощью командной строки. Помните, что демоны и сервисы могут блокировать доступ к некоторым файлам и пока сервисы работают заменить такие файлы копиями из бэкапа невозможно! В этом случае придется писать код для старта и остановки этих сервисов.
- Автоматизированная система хранения результатов автоматических тестов.
-
Если для хранения результатов автоматических тестов вы используете тот же тип базы данных что и приложение (это совсем не обязательно) можете использовать те же компоненты, иначе – используйте интерфейс той базы данных (web, command line), в которой вы храните тесты, либо command line для доступа к файловой системе.
- Автоматизированная система формирования и рассылки результатов тестов.
-
Здесь проще использовать собственные java-классы, либо shell/vba скрипты, так как функционал несложный, а найти такой бесплатный инструмент, который полностью удовлетворял бы желаемому вами формату – непросто. Но поискать все же стоит – это может сэкономить вам время потом.
На данном этапе вам нужно будет определиться с начальным набором сторонних компонентов, которые вы будете использовать. К выбору нужно подходить осознавая тот факт, что замена одного компонента может вылиться в значительную переработку кода. Тем не менее излишне задерживаться с выбором тоже не стоит. К примеру, если у вас есть 2 библиотеки, которые покрывают ваши нужды на 90%, вы можете потратить очень много времени лишь сравнивая их возможности в надежде выявить наиболее подходящую. На этапе выбора редко получается предвидеть все случаи использования библиотеки, поэтому сделать "100% правильный выбор" за разумное время практически невозможно. Если вы стоите перед похожей дилеммой (~90% / ~90%) попробуйте начать использовать ту библиотеку, которая вам больше нравится (к примеру - имеет более понятный и продуманный API). Примерно за то же время что вы проведете сравнивая 2 библиотеки и получив результат "наверное подходит" / "наверное не подходит", вы сможете получить более точную информацию "подходит" / "не подходит" об одной из них. Это гораздо более полезная информация. К тому же, если библиотека вам подходит, вы получите выигрыш во времени - ведь вы уже начали ее использовать!
4. Оценка объемов работы.
После того как выбор компонентов закончен, есть резон потратить некоторое время на осмысление того, что вам предстоит сделать. Естественно, готовые компоненты не нуждаются в оценке. Оценивать нужно работу по их интерграции в вашу систему.
Оценку лучше делать после того как вы дочитаете статью до конца - возможно некоторые вещи станут более понятны.
Существует много методик оценок времени на разработку, однако, в основном, они опираются на предыдущий опыт. Я приведу здесь пару ссылок на англоязычные ресурсы, которые считаю полезными:
Estimation in software engineering
От себя добавлю чуть-чуть:
- Если вы знаете как решить проблему с помощью известного вам инструментария - лучше решить эту проблему именно таким способом. Вы сможете запланировать время исходя из предыдущего опыта. Если кто-то где-то сделал более эффективную систему используя другой инструментарий - не обольщайтесь - скорее всего в реализации есть множество нюансов на нахождение которых вы потратите времени больше, чем выиграете. Не хочется отговаривать от освоения использования новых технологий, но лучше заняться этим в случае если результат не критичен, либо не критично время на разработку, либо в свободное от работы время :)
- Если вы не занимались планированием раньше - лучше спросить совета у тех кто занимался и, желательно, трудится на том же проекте. Конкретные рекомендации давать очень сложно - слишком разные бывают начальные условия, именно поэтому книги по оценкам оперируют достаточно общими терминами.
5. Разработка. Практические рекомендации.
Всегда помните о том, что не существует универсальных рецептов! Можно рассматривать частные случаи, можно рассматривать рекомендации, но 100% ситуаций нельзя эффективно покрыть используя один подход. Поэтому отнеситесь к нижеизложенному критически. Это то, что работало для меня, но ваша система скорее всего имеет отличия.
Итак, начнем с алгоритма работы инфраструктуры тестов. Он может быть таким:
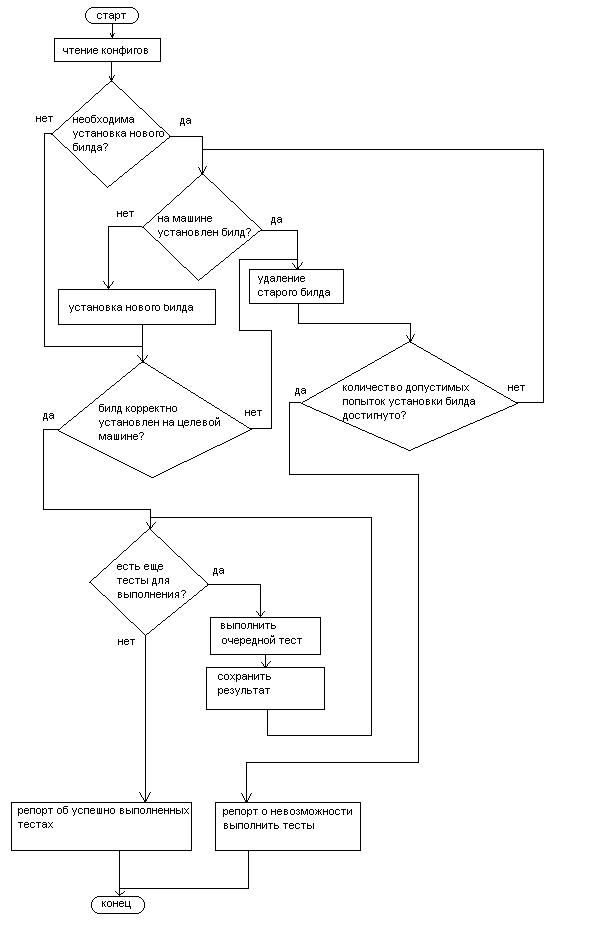
Как видно из схемы, алгоритм, в общем, несложный. Я сознательно опустил полное восстановление системы, так как оно не везде нужно. Основная сложность будет заключаться в безглючной реализации всех этих действий и связывании их в одну работающую систему. Причем должны правильно обрабатываться все ситуации - это обязательно нужно проверять после любых внесенных в алгоритм изменений!
Выбор языка реализации за вами, но необходимо убедиться что язык поддерживается на всех необходимых вам платформах. Например для обеспечения кроссплатформенности Linux + Windows + AIX прекрасно подходит Perl и Java.
5.1 WEB/GUI
В этой части хотелось бы главным образом коснуться архитектуры, позволяющей эффективно работать с форм-ориентированными приложениями, а также позволяющей эффективно использовать код автотестов.
То, с чего почти все начинают написание автотестов - это рекординг. Т.е. простая запись последовательности нахождения и заполнения/нажатия/выбора элемента активной формы. В результате такого рекординга, как правило, создается скрипт и набор свойств элементов с которыми этот скрипт взаимодействует (либо как отдельный файл, либо как часть того же скрипта). Причем данные, которые использовались при заполнении формы скорее всего находятся тут же - в скрипте.
Посмотрим, как может быть улучшен такой скрипт. Для простоты предположим, что выбранный нами инструмент поддерживает объектно ориентированный подход - то есть мы можем создавать классы, иерархии классов (с наследованием) и использовать в тестах экземпляры этих классов. Пойдем от простого к сложному.
1. Выделяем классы форм
Для каждой формы создаем отдельный класс, в котором содержатся методы для работы с ней (проверка что данная форма загружена, внесение/проверка данных в элементах формы, навигация на другие формы, закрытие формы и т.п.). Таким образом тест будет представлять уже не беспорядочный набор операций (смысл которых может стать понятен не сразу), а набор параметризованных операций с формами.
Пример:
Application.startNewInstance();
LoginForm login = (LoginForm) Application.getCurrentForm();
MainForm main = login.login("user","password");
login = main.logout();
Даже без доступа к коду функций login и logout понятно, что должно происходить в тесте. А это значит, что для разбора проблем и внесения изменений потребуется гораздо меньше времени!
Этот подход был недавно описан в блоге Google, впрочем, это не мешало успешно использовать его задолго до этого описания на некоторых проектах, в которых мне посчастливилось принимать участие.
2. Выносим общие методы взаимодействия с элементами из классов форм в общий суперкласс
Создаем класс от которого наследуются все формы и выносим в него общие методы для взаимодействия с элементами. Это очень удобно, если к примеру, сначала элемент нужно найти, затем активировать, а затем установить в него данные. Суперкласс позволяет описать эти последовательности действий в одном месте и впоследствии быстро и безболезненно вносить в них изменения. Также сюда можно вынести методы, проверяющие что именно эта форма открыта и активна (например - по уникальному ключевому элементу управления находящемуся на форме, по заголовку, http и т.п.). Также здесь можно реализовать настраиваемую паузу перед/после взаимодействия с элементами управления и т.п.
3. Выносим данные теста из скрипта в подгружаемый файл (поддержка Data-Driven testing)
Создаем файл (например в var=value формате) в который выносим все данные которые используются в скрипте. Подгружаем эти данные во время выполнения. Это позволяет запускать один и тот же скрипт используя разные данные для него. Можно создать несколько наборов, либо генерировать наборы данных "на лету". Эта концепция реализована в софте от Rational (ныне - подразделение IBM) и называется такой набор данных datapool, правда сделано жутко криво и неудобно, но никто не мешает сделать собственную реализацию, как это сделали мы. Кстати, это попутно решило кучу проблем.
4. Создаем кейворды (поддержка Keyword-Driven testing)
Кейворды - это мини-скрипты. Например, кейворд логина может запускать страницу логина, проверять что она открыта, заполнять поля логина и пассворда нужными значениями, нажимать кнопку логина, проверять что пользователь успешно залогинен. И все это - с помощью одного метода! Для этого вам нужно будет создать библиотеку кейвордов. Кейворд может оперировать несколькими страницами.
К примеру тест может выглядеть так :
KwrdLib.getKeyword("login").execute(new String[] {"user", "password"});
KwrdLib.getKeyword("createNewUser").execute(new String[] {"user2", "password2"});
KwrdLib.getKeyword("logout").execute(new String[] {});
KwrdLib.getKeyword("login").execute(new String[] {"user2", "password2"});
KwrdLib.getKeyword("logout").execute(new String[] {});
Джедаи java 1.6 могут вообще использовать Enum с Reflections, чтобы синтаксис обращений к кейвордам заставлял глаз радоваться, но это материал для другой статьи. Будет выглядеть примерно так: LOGIN.execute(new String[] {"user", "password"});
CREATE_NEW_USER.execute(new String[] {"user2", "password2"});
...
Соответственно, в классе KwrdLib будет статический метод getKeyword который будет возвращать экземпляр нужного класса кейворда по имени (с точки зрения java-программирования логичнее, конечно, использовать здесь Reflections).
public static Keyword getKeyword(String keywordName) {
...
if (keywordName.equals("login")) {
return new LoginKeyword();
}
...
}
}
А уже непосредственно в классе кейворда будет описана манипуляция с формами:
public void execute(String[] data) {
//проверяем что набор данных достаточный
if (data.length < 2) {
throw new RuntimeException("Invalid dataset for LoginKeyword: at least 2 params should be provided.");
}
//проверяем что открыта нужная форма
if (!(Application.getCurrentForm() instanceof LoginForm)) {
throw new RuntimeException("Invalid form opened: " + Application.getCurrentForm() + "; Expected: LoginForm");
}
//выполняем процедуру логина
LoginForm login = (LoginForm) Application.getCurrentForm();
MainForm main = login.login("user","password");
//сохраняем текущую форму
Application.setCurrentForm(main);
}
В примере использован java код так как этот язык весьма универсален и обеспечивает богатые возможности работы с классами. Те же примеры (например библиотека кейвордов) могут быть более удобно организованны с помощью Enum классов, но здесь упор сделан в первую очередь на понятность концепции. Также из примера видно, что кейворд подразумевает начало выполнения с определенной формы и завершение выполнения на определенной форме. Очень хорошо, если вы сможете организовать свои кейворды таким образом, чтобы большинство из них (>90%?) начинались и заканчивались на одной и той же открытой форме - например это может быть окно основного приложения в исходном состоянии.
PS Класс Application - это вспомогательный класс для работы с приложением. В нем можно хранить текущее состояние, методы вызова, закрытия и возврата в "исходное состояние" тестируемого приложения. Оформить можно в виде синглетона.
5.2 Файловая система
Для работы с файловой системой очень удобно написать свой интерфейс. Причем вы в дальнейшем сможете использовать его на других проектах! Вам может понадобится также работать с удаленными файловыми системами и очень здорово, если интерфейс будет одинаковый! Т.е. вы можете работать с объектами через интерфейс не думая о том локальная это файловая система или удаленная!
Например в моей практике был успешно реализован единый интерфейс для работы с локальной системой через Java Virtual Machine из которой запускались тесты и с удаленными файловыми системами WINDOWS AIX и LINUX через SSH с помощью библиотек jsch и j2ssh.
Уделите внимание таким операциям как:
- копирование/создание/удаление/проверка существования файлов
- архивация/разархивация файлов и каталогов
- копирование файлов с/на целевую файловую систему
- поиск в файлах по паттерну (логи) / изменение содержимого текстовых файлов (конфиги)
- выполнение команд на удаленной системе и получение стандартного вывода (stdout) и ошибок (errout) от них.
5.3 Сервисы и демоны
Если вам приходится управлять состоянием сервисов/демонов на различных платформах, также удобно иметь единый интерфейс, который будет прятать реализацию (последовательность и синтаксис команд) управления сервисами/демонами для конкретной платформы. В этом случае вам не нужно будет постоянно помнить о том, на какой платформе приходится работать. Опять же, проще добавить поддержку новых платформ, т.е. ваша система становится более расширяемой.
Общий алгоритм такой:
1. Проверка состояния.
2. Если сервис/демон уже в нужном состоянии - выход.
3. Если достигнут таймаут запуска/остановки сервиса - выход с ошибкой.
4. Если сервис/демон в промежуточном состоянии (starting|stopping) - ждем таймаут и идем на шаг1.
5. Отдаем команду запуска/остановки сервиса.
6. Проверка состояния.
7. Если сервис/демон в нужном состоянии - выход.
8. Если достигнут таймаут запуска/остановки сервиса - выход с ошибкой.
9. Если сервис/демон в промежуточном состоянии (starting|stopping) - ждем таймаут и идем на шаг6.
Шаги 1-4 и 6-9 похожи - можно оптимизировать, но для понятности здесь не буду этого делать :)
5.4 Базы данных
Единый интерфейс для работы с базами данных будет полезен, если тестируемое приложение должно поддерживать работу на нескольких типах баз данных. Соответственно, есть потребность тестировать приложение на каждой такой базе. В этом случае полезно использовать hibernate, если вы пишете тесты на Java и структура баз одинакова. Если структура баз разная, то каждая такая структура потребует отдельный набор классов. Hibernate и тут будет полезен, но не настолько эффективен как при одинаковой структуре баз. Впрочем если в java-приложении сужествует поддержка нескольких типов баз, то Hibernate скорее всего уже используется, и, вероятнее всего, структура баз будет одинакова.
5.5 Отчеты
Еще одна большая тема. Всегда нужно помнить о том что отчеты - это результат вашей работы. То есть именно по нему будут судить о вас и о вашей работе. Нерегулярные, плохочитаемые(представление информации) и неинформативные(содержание) отчеты будут только занимать место в почтовом ящике - вряд ли кто-то станет их читать.
5.5.1 Содержимое результатов автоматизированного теста
В результате выполнения теста для последующего анализа полезно получить и сохранить следующую информацию (список можно расширить по необходимости):
- Время начала выполнения теста
- Время завершения выполнения теста
- Результат (passed / failed / blocked)
- Полный лог выполнения теста и крайне желательно - с метками времени для каждой записи в логе
- Номер билда для которого проводился тест
- Конфигурация (аппаратная платформа + настройки) на которой проводился тест. (Актуально только если используется несколько конфигураций)
- Скриншот (в сучае отличного от passed результата)
Естественно, все можно кастомизировать под ваши нужды. Например - добавить сбор и архивацию определенных логов с сервера для упрощения анализа ошибок. Своеобразный снимок енвайрмента.
5.5.2 Хранение результатов автоматизированных тестов
Лучше всего использовать для этих целей БД, например ClearQuest, MySQL, Postgre, либо другую. Но для небольших проектов пойдет и файловая система.
5.5.3 Содержание отчета
Опытным путем я пришел к следующему формату отчета (у вас он, естественно, может отличаться):
Заголовок:
- Конфигурация (если их несколько)
- Билд
- Количество запущенных тесткейсов
- Количество успешно завершенных тесткейсов
- Подробное описание конфигурации и параметров, на которых проводился тест.
- Статистика реультатов (passed / failed / blocked) теста
- Полная таблица с самоописательными названиями тесткейсов и их результатами passed / failed / blocked (со ссылкой на детальную информацию о результате - см. 5.5.1).
- Ссылка на историю результатов (если ее можно где-нибудь посмотреть)
Полезно иметь инструмент позволяющий по вашим результатам тестов составить историю - по ней можно сравнивать результаты для разных билдов, смотреть когда последний раз тест кейс был успешно выполнен и т.п. Т.е. вообще такой инструмент относится к украшательствам и может быть выполнен в последюю очередь, но иметь его под рукой очень удобно как для анализа результатов тестов, так и для презентации вашей системы автоматизированного тестирования, так как результаты в таком представлении наиболее наглядны.
5.5.4 Рассылка результатов
Рассылайте ваши отчеты:
- Менеджеру(ам) проекта
- Менеджеру(ам) по тестированию
- Тестлиду(ам)
- Всем, кто попросит!!! (см. следующую главу)
6 Визуализация работы
Самый интересный вопрос автоматизации - а как же сделать так, чтобы всю эту сложную и творческую работу вам дали довести до победного финала? Объем задач не маленький, а собрать в одну команду нескольких толковых автоматизаторов получается отнюдь не всегда (впрочем были в моей практике такие команды - нужно только сильно захотеть и иметь в запасе хотя бы год на подбор сотрудников). То есть часто приходится работать одному, максимум - вдвоем.
Давайте представим как выглядит автоматизатор тестов со стороны в начале работы над проектом. Приходит на работу с утра, смотрит весь день в монитор, стучит по клавишам, вечером собирается и уходит. На вопросы менеджера о текущей работе засыпает его деталями и проблемами, на вопросы менеджера о готовности отсылает в далекую перспективу. Также может периодически требовать дополнительные рабочие станции. Разработчики менеджеру в понимании происходящего помочь могут весьма условно, так как у них другая специфика работы.
Если на вашем проекте все именно так и происходит - сделаю ставку на то, что автоматизация закончена и внедрена не будет. Ведь менеджер - это тот кто должен обеспечить выполнение проекта в сроки, а также его рентабельность. И если ему непонятно чем занимается на проекте человек - значит в его глазах это пустая трата проектных средств. Именно поэтому автоматизатора будут постоянно пытаться занять другой "полезной" работой - ручными тестами, поддержкой тестовой лаборатории или программированием - ведь эти задачи хорошо визуализируются (т.е. видны, ясны и понятны менеджеру).
Знакомо?
Кроме возможности довести работу до конца, визуализация дает ряд побочных положительных эффектов:
- Фидбек - Очень здорово, когда написанную вами систему использует еще кто-то и делится идеями по улучшению. Часто "замыленным" взглядом не видно простых вещей. Чем больше людей знают о вашей системе и о том как она работает - тем больше поступает фидбека! Лично я позитивному неконструктивному фидбэку (" - Молодец! Отличная работа! Спасибо! Так держать! и т.п.") предпочитаю негативный, но конструктивный фидбек (" - Если вот это переделать вот так - будет работать быстрее в 2 раза, а наглядность только улучшится!" или "эта настройка не нужна - ей все равно никто не пользуется"). Думаю не надо объяснять - почему :)
- Правильная приоритезация работы - Визуализация - это работа по принципу agile. Чтобы быть все время "на виду" нужно как можно быстрее сделать рабочий прототип, а затем расширять его функциональность в соответствии с нуждами проекта. При этом система все время поддерживается в рабочем состоянии и виден прогресс! А результаты доступны как можно раньше. Кроме этого происходит устранение рисков на самой ранней стадии - 90% функционала вашей автотест-системы будет работать уже после 10% потраченного времени (естественно, оценка среднепотолочная, некоторые говорят о 20% и 80% соответственно). Например моя любимая последовательность приоритетов следующая:
- 2-4 рабочих тест скрипта - снимает риск неправильно выбранного инструмента и распознавания им элементов управления приложения. Позволяет разработать эффективную архитектуру тестовых сценариев (да-да, не все автотесты пишутся рекордингом).
- основная инфраструктура: инсталляция, деинсталляция, восстановление рабочей среды, рассылка результатов - позволяет построить законченную автоматизированную систему и начать ее использование. Соответственно снимает риск неполучения такой системы в финале из-за каких либо программных либо аппаратных проблем или ограничений.
- Оставшиеся тесты - основные риски с совместимостью приложения и инструмента тестирования уже сняты, так что работе почти ничто не мешает.
- Украшательства и статистика - здесь риски еще меньше.
- Популяризация автоматизированного тестирования - Если кто-то имел положительный опыт автоматизации он никогда не забудет ощущение от того как тонны скучной и унылой работы превращаются в интереснейшие и нетривиальные задачи, а затем выполняются в разы быстрее, чем это может сделать человек. А в это время команда ручного тестирования может сосредоточится на действительно важных проблемах!
Теперь пару слов о том что же представляет собой "визуализация". Возможны 2 варианта которые принципиально схожи, но немного различны в деталях. Назовем их "визуализация на большом проекте" и "визуализация на небольшом проекте". В случае небольшого проекта сосредочьте свои усилия на менеджере проекта. Это тот кто будет продвигать бюджет по автоматизации.
Небольшой проект:
- Обсуждайте свои задачи с менеджером, даже если вы ставите их себе сами. Вы должны быть уверены что он знает и понимает чем вы сейчас заняты, что вы уже сделали и какие у вас планы.
- Подпишите на свои "рассылки" результатов тестирования как можно больше менеджеров. Им это будет давать ощущение "руки на пульсе" проекта, а вам - фидбэк и саморекламу. Также подпишите интересующихся коллег - они основные генераторы идей, когда у вас идеи уже закончились.
- Постоянно улучшайте, расширяйте и стабилизируйте свою систему - это поможет меньше отвлекаться на проблемы с ней впоследствии, а также поможет быстрее решать новые задачи.
На большом проекте вы можете быть предоставлены сами себе с общей целью действовать в интересах команды. В случае если у вас есть непосредственный менеджер - актуален вариант визуализации для небольшого проекта.
Большой проект:
-
Знайте кто решает вопрос быть или не быть автоматизации (т.е. распределяет бюджет). Это может быть не 1 человек. Это может быть в том числе и заказчик!
Все то же что и на небольшом проекте, только вместо понятия "менеджер" используйте тех кто попадает в пункт 1 :) Естественно, вы вряд ли сможете обсудить свои задачи со всеми этими людьми, но можно выяснить их интересы (какие фичи сделают их счастливыми) и стимулировать их с помощью своих репортов!
Вот как-то так...
Автор: Владимир Антонов